2.2 Boundary testing
Off-by-one mistakes are a common cause for bugs in software systems.
As developers, we have all made mistakes such as using a "greater than" operator (>) where it had to be a "greater than or equal to" operator (>=).
Interestingly, programs with such a bug tend to work well for most of the provided inputs. They fail, however, when the input is "near the boundary of condition".
In this chapter, we explore boundary testing techniques.
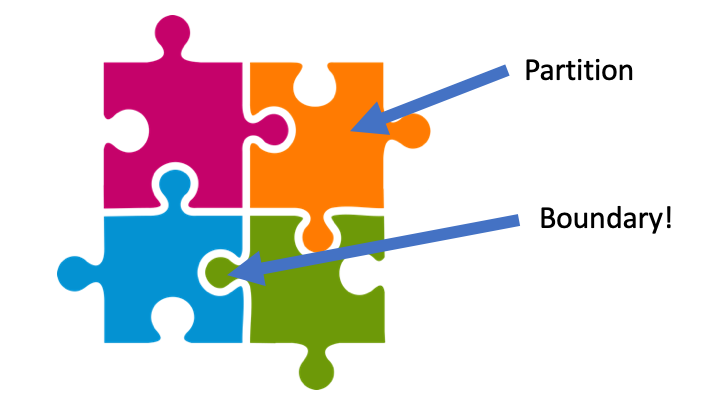
Boundaries in between classes/partitions
In the previous chapter, we studied specification-based techniques and, more specifically, we understood the concept of classes/partitions. When we devise classes, these have "close boundaries" with the other classes. In other words, if we keep performing small changes to an input that belongs to some partition (e.g., by adding +1 to it), at some point this input will belong to another class. The precise point where the input changes from one class to another is what we call a boundary. And this is precisely what boundary testing is about: to make the program behave correctly when inputs are near a boundary.
More formally, we can find such boundaries by finding a pair of consecutive input values , where belongs to partition A, and belongs to partition B.
Let us apply boundary testing in a concrete example:
Requirement: Calculating the number of points of a player
Given the score of a player and the number of remaining lives of the player, the program does the following:
- If the player's score is below 50, then it always adds 50 points on top of the current points.
- If the player's score is greater than or equals to 50, then:
- if the number of remaining lives is greater than or equal to 3, it triples the score of the player.
- otherwise, it adds 30 points on top of the current points.
A possible implementation for this method can be:
public class PlayerPoints {
public int totalPoints(int currentPoints, int remainingLives) {
if(currentPoints < 50)
return currentPoints+50;
return remainingLives < 3 ? currentPoints+30 : currentPoints*3;
}
}
When devising the partitions to test this method, a tester might come up with the following partitions:
- Less points: Score < 50
- Many points but little lives: Score >= 50 and remaining lives < 3
- Many points and many lives: Score >= 50 and remaining lives >= 3
Those partitions would lead testers to devise at least three test cases, one per partition:
public class PlayerPointsTest {
private final PlayerPoints pp = new PlayerPoints();
@Test
void lessPoints() {
assertEquals(30+50, pp.totalPoints(30, 5));
}
@Test
void manyPointsButLittleLives() {
assertEquals(300+30, pp.totalPoints(300, 1));
}
@Test
void manyPointsAndManyLives() {
assertEquals(500*3, pp.totalPoints(500, 10));
}
}
However, a tester who is aware of boundaries also devises test cases that explore the boundaries of the domain. Let us explore them:
Boundary 1: When the score is strictly smaller than 50, it belongs to partition 1. If the score is greater than or equal to 50, it belongs to partitions 2 and 3. Therefore, we observe the following boundary: when the score changes from 49 to 50, the partition it belongs to also changes (let us call this test B1).
Boundary 2: Given a score that is greater than or equal to 50, we observe that if the number of remaining lives is smaller than 3, it belongs to partition 2; otherwise, it belongs to partition 3. Thus, we just identified another boundary there (let us call this test B2).
We can visualise these partitions with their boundaries in a diagram.

In our example, the tester would then devise and automate test cases B1 and B2. Given that a boundary is composed of two different input values, note that each boundary will require at least two test cases:
For B1:
- B1.1 = input={score=49, remaining lives=5}, output={99}
- B1.2 = input={score=50, remaining lives=5}, output={150}
For B2:
- B2.1 = input={score 500, remaining lives=3}, output={1500}
- B2.2 = input={score 500, remaining lives=2}, output={530}
An implementation using JUnit is shown below. Note that we have written just a single test for each pair of test cases. This makes the test more cohesive. If there is a boundary bug, a single test will let us know.
@Test
void betweenLessAndManyPoints() {
assertEquals(49+50, pp.totalPoints(49, 5));
assertEquals(50*3, pp.totalPoints(50, 5));
}
@Test
void betweenLessAndManyLives() {
assertEquals(500*3, pp.totalPoints(500, 3));
assertEquals(500+30, pp.totalPoints(500, 2));
}
You might have noticed that, for B1, in case of score < 50, remaining lives makes no difference.
However, for score >= 50, remaining lives does make a difference, as the output can vary according to its value.
And for the B1.2 test case, we chose remaining lives = 5, which makes the
condition true.
You might be wondering whether you also need to devise another test case, B1.3, where the remaining lives condition would be exercised as false.
If you are looking to test all possible combinations, then the answer is yes. However, in longer conditions, full of boundaries, the number of combinations might be too high, making it unfeasible for the developer to test them all. Later in this chapter, we will learn how to choose values for the "boundaries that we do not care about".
On and off points
Given some initial intuition on how to analyse boundaries, let us define some terminology:
- On-point: The on-point is the value that is exactly on the boundary. This is the value we see in the condition itself.
- Off-point: The off-point is the value that is closest to the boundary and that flips the condition. If the on-point makes the condition true, the off point makes it false and vice versa. Note that when dealing with equalities or inequalities (e.g. or ), there are two off-points; one in each direction.
- In-points: In-points are all the values that make the condition true.
- Out-points: Out-points are all the values that make the condition false.
Example: Suppose we have a program that adds shipping costs when the total price is below 100. The condition used in the program is .
- The on-point is , as that is the value that is precisely in the condition.
- The on-point makes the condition false (100 is not smaller than 100), so the off-point should be the closest number that makes the condition true. This will be , as is true.
- The in-points are the values which are smaller than or equal to . For example, 37, 42, 56.
- The out-points are all values which are larger than or equal to . For example, 325, 1254, 101.
We show all these points in the diagram below.

Let us now study a similar but slightly different condition: (the only difference is that, in this one, we use "less than or equal to"):
- The on-point is still : this is the value that is precisely in the condition.
- The condition is evaluated as true for the on-point. So, the off-point should be the closest number to the on-point, but making the condition false. The off-point is thus .

Note that, depending on the condition, an on-point can be either an in- or an out-point.
As a tester, you devise test cases for these different points: a test case for the on-point, a test case for the off-point, a test case for a single in-point (as all in-points belong to the same equivalence partition), and a test case for a single out-point (as all out-points also belong to the same equivalence partition).
Note that on and off points are also in or out points. Therefore, tests that focus only on the on and off points would also be testing in and out points. In fact, some authors argue that testing boundaries is enough. Moreover, a test that exercises an in-point that is far away from the boundary might not have a strong fault detection capability. Why would we need them?
There is no perfect answer here. We suggest:
- If the number of test cases is indeed too high, and it is just too expensive to do them all, prioritization is important, and we suggest testers to indeed focus on the boundaries.
- Far away in/out points are sometimes easier to be seen or comprehended by a tester who is still learning about the system under test, and exploring its boundaries (exploratory testing). Deciding whether to perform such a test is thus a decision that a tester should take, taking the costs into account.
Revisiting the "chocolate bars" problem
Let's revisit the example from the a previous chapter. There, we had a program where the goal was to return the number of bars needed in order to build some boxes of chocolates:
Chocolate bars
A package should store a total number of kilos. There are small bars (1 kilo each) and big bars (5 kilos each). We should calculate the number of small bars to use, assuming we always use big bars before small bars. Return -1 if it can't be done.
The input of the program is thus the number of small bars, the number of big bars, and the total number of kilos to store.
And these were the classes we derived after applying the category/partition method:
- Need only small bars. A solution that only uses the provided small bars.
- Need only big bars. A solution that only uses the provided big bars.
- Need small + big bars. A solution that has to use both small and big bars.
- Not enough bars. A case in which it's not possible, because there are not enough bars.
- Not from the specs: An exceptional case.
As we saw in the previous chapter, the following code passed all the tests we derived:
public class ChocolateBars {
public static final int CANNOT_PACK_BAG = -1;
public int calculate(int small, int big, int total) {
int maxBigBoxes = total / 5;
int bigBoxesWeCanUse = Math.min(maxBigBoxes, big);
total -= (bigBoxesWeCanUse * 5);
if(small <= total)
return CANNOT_PACK_BAG;
return total;
}
}
However, the following input makes the program to fail: (2,3,17)!
Note that the input (2,3,17) belongs to the need small + big bars partition. In this case,
the program should make use of all the big bars (there are 3 available) and then all the small bars available (there are
2 available). Note that the buggy program would work if we had 3 available small bars (having (3, 3, 17) as input).
The bug lies on the if condition. It should be if(small < total) instead of
if(small <= total):
public class ChocolateBars {
public static final int CANNOT_PACK_BAG = -1;
public int calculate(int small, int big, int total) {
int maxBigBoxes = total / 5;
int bigBoxesWeCanUse = Math.min(maxBigBoxes, big);
total -= (bigBoxesWeCanUse * 5);
// we fixed the bug here!
if(small < total)
return CANNOT_PACK_BAG;
return total;
}
}
This bug is clearly an instance of a bug that should have been detected by boundary testing. The problem is that this boundary is just less explicit from the requirements.
As we defined at the beginning of this chapter, boundaries also happen when we are going from "one partition" to another. There is a "single condition" that we can use as clear source. In these cases, what we should do is to devise test cases for a sequence of inputs that move from one partition to another.
Let us focus on the bug caused by the (2,3,17) input:
(1,3,17)should return not possible (1 small bar is not enough). This test case belongs to the not enough bars partition.(2,3,17)should return 2. This test case belongs to need for small + big bars partition.
The (1,3,17) and (2,3,17) inputs exercise precisely the boundary between the not enough bars and the need for small + big bars partitions.
Let us now explore the boundaries between other partitions. The figure below shows which boundaries can happen (and that we should test):

Looking at the only big bars partition, we should find inputs that transition from this partition to another one:
(10, 1, 10)returns 5. This input belongs to the need small + big bars partition.(10, 2, 10)returns 0. This input belongs to the need only big bars partition.
Finally, with the only small bars partition:
(3, 2, 3)returns 3. We need only small bars here, and therefore, this input belongs to the only small bars partition.(2, 2, 3)returns -1. We can't make the boxes. This input belongs to the Not enough bars partition.
A partition might have boundaries with more than just a single other partition. The only small bars partition has boundaries not only with the not enough bars partition (as we saw above), but also with the only big bars partition:
(4, 2, 4)returns 4. We need only small bars here, and therefore, this input belongs to the only small bars partition.(4, 2, 5)returns 0. We need only big bars here, and therefore, this input belongs to the only big bars partition.
A lesson we learn from this example is that boundary bugs may not
only emerge out of "clear if conditions" we
see in the implementation. Boundary bugs also happen in more subtle
interactions among partitions.
Automating boundary testing with JUnit (via parameterised tests)
You might have noticed that in the domain matrix we always have a certain number of input values and, implicitly, an expected output value. We could just implement the boundary tests by making a separate method for each test, or by grouping them per boundary, as we have been doing so far.
However, the number of test methods can quickly become large and unmanageable. Moreover, the code in these test methods will be largely the same, as they all have the same structure, only with different input and output values.
Luckily, JUnit offers a solution where we can generalise the implementation of a test
method, and run it with different inputs and expected outputs: parameterised Tests.
As the name suggests, with a parameterised test, developers
can define a test method with parameters.
To define a parameterised test, you make use of the @ParameterizedTest annotation,
instead of the usual @Test annotation.
For each parameter you want to pass to the "template test method", you define a
parameter in the method's parameter list (note that so far, all our JUnit methods had
no parameters). For example, a test method t1(int a, int b) receives two parameters,
int a and int b. The developer uses these two variables in the body of the test
method, often in places where the developer would have a hard-coded value.
The next step is to feed JUnit with a list of inputs which will be passed
to the test method.
In general, these values are provided by a Source.
Here, we will make use of a CsvSource.
With it, each test case is given as a comma-separated list of input values.
To execute multiple tests with the same test method,
the CsvSource expects list of strings, where each string represents
the input and output values for one test case.
The CsvSource is an annotation itself, so in an implementation
it would look like the following: @CsvSource({"value11, value12", "value21, value22", "value31, value32", ...})
@ParameterizedTest(name = "small={0}, big={1}, total={2}, result={3}")
@CsvSource({
// The total is higher than the amount of small and big bars.
"1,1,5,0", "1,1,6,1", "1,1,7,-1", "1,1,8,-1",
// No need for small bars.
"4,0,10,-1", "4,1,10,-1", "5,2,10,0", "5,3,10,0",
// Need for big and small bars.
"0,3,17,-1", "1,3,17,-1", "2,3,17,2", "3,3,17,2",
"0,3,12,-1", "1,3,12,-1", "2,3,12,2", "3,3,12,2",
// Only small bars.
"4,2,3,3", "3,2,3,3", "2,2,3,-1", "1,2,3,-1"
})
void boundaries(int small, int big, int total, int expectedResult) {
int result = new ChocolateBars().calculate(small, big, total);
Assertions.assertEquals(expectedResult, result);
}
Some developers prefer not to pass a list of CSV/strings. For those, JUnit provides a @MethodSource option, which allows developers to provide the input for the parameterised test through a method. The developer simply needs to define a method that returns a Stream<Arguments> (and set the name of this method in the @MethodSource annotation). See the implementation below:
public class ChocolateBarsTest {
@ParameterizedTest(name = "small={0}, big={1}, total={2}, result={3}")
@MethodSource("generator")
void boundaries(int small, int big, int total, int expectedResult) {
int result = new ChocolateBars().calculate(small, big, total);
Assertions.assertEquals(expectedResult, result);
}
private static Stream<Arguments> generator() {
return Stream.of(
// The total is higher than the amount of small and big bars.
Arguments.of(1,1,5,0),
Arguments.of(1,1,6,1),
Arguments.of(1,1,7,-1),
Arguments.of(1,1,8,-1),
// No need for small bars.
Arguments.of(4,0,10,-1),
Arguments.of(4,1,10,-1),
Arguments.of(5,2,10,0),
Arguments.of(5,3,10,0),
// Need for big and small bars.
Arguments.of(0,3,17,-1),
Arguments.of(1,3,17,-1),
Arguments.of(2,3,17,2),
Arguments.of(3,3,17,2),
Arguments.of(0,3,12,-1),
Arguments.of(1,3,12,-1),
Arguments.of(2,3,12,2),
Arguments.of(3,3,12,2),
// Only small bars.
Arguments.of(4,2,3,3),
Arguments.of(3,2,3,3),
Arguments.of(2,2,3,-1),
Arguments.of(1,2,3,-1)
);
}
}
You can see all these implementation in our GitHub repository: https://github.com/sttp-book/code-examples/tree/master/src/test/java/tudelft/chocolate.
The CORRECT way
The book Pragmatic Unit Testing in Java 8 with JUnit, by Langr, Hunt, and Thomas, has an interesting discussion about boundary conditions. Authors call it the CORRECT way, as each letter represents one boundary condition to consider:
Conformance:
- Many data elements must conform to a specific format. Example: e-mail addresses (always name@domain). If you expect an e-mail address, and you do not receive one, your software might crash.
- Required action: Test what happens when your input is not in conformance with what is expected.
Ordering:
- Some inputs might come in a specific order. Imagine a system that receives different products to be inserted in a basket. The order of the data might influence the output. What happens if the list is ordered? Unordered?
- Required action: Make sure our program works even if the data comes in an unordered manner (or return an elegant failure to user, avoiding the crash).
Range:
- Inputs should usually be within a certain range. Example: Age should always be greater than 0 and smaller than 125.
- Required action: Test what happens when we provide inputs that are outside of the expected range.
Reference:
- In OOP systems, objects refer to other objects. Sometimes the relationships between the objects are extensive and there may be external dependencies. What happens if these dependencies do not behave as expected?
- Required action: When testing a method, consider:
- What it references outside its scope
- What external dependencies it has
- Whether it depends on the object being in a certain state
- Any other conditions that must exist
Existence:
- Does "something" really exist? What if it does not? Imagine you query a database, and your database returns an empty result. Will our software behave correctly?
- Required action: Does the system behave correctly when something that is expected to exist, does not?
Cardinality:
- In simple words, our loop performed one step less (or more) than it should.
- Required action: Test loops in different situations, such as when it actually performs zero iterations, one iterations, or many. (Loops are further discussed in the structural testing chapter).
Time
- Systems rely on dates and times. What happens if the system receives inputs that are not ordered in regards to date and time?
- Timeouts: Does the system handle timeouts well?
- Concurrency: Does the system handle concurrency well?
Equivalent classes and boundary analysis altogether
We discussed equivalent class analysis and boundary testing. In practice, testers combine both, in what they call domain testing.
We suggest the following strategy when applying domain testing, highly influenced by how Kaner et al. do:
- We read the requirement
- We identify the input and output variables in play, together with their types, and their ranges.
- We identify the dependencies (or independence) among input variables, and how input variables influence the output variable.
- We perform equivalent class analysis (valid and invalid classes).
- We explore the boundaries of these classes.
- We think of a strategy to derive test cases, focusing on minimizing the costs while maximizing fault detection capability.
- We generate a set of test cases that should be executed against the system under test.
See a series of domain testing examples in our appendix.
Exercises
Exercise 1. We have the following method.
public String sameEnds(String string) {
int length = string.length();
int half = length / 2;
String left = "";
String right = "";
int size = 0;
for(int i = 0; i < half; i++) {
left += string.charAt(i);
right = string.charAt(length - 1 - i) + right;
if (left.equals(right))
size = left.length();
}
return string.substring(0, size);
}
Perform boundary analysis on the condition in the for-loop: i < half, i.e. what are the on- and off-point and the in- and out-points?
You can give the points in terms of the variables used in the method.
Exercise 2.
Perform boundary analysis on the following equality: x == 10.
What are the on- and off-points?
Exercise 3.
A game has the following condition: numberOfPoints <= 570.
Perform boundary analysis on the condition.
What are the on- and off-point of the condition?
Also give an example for both an in-point and an out-point.
Exercise 4.
Regarding boundary analysis of inequalities (e.g., a < 10), which of the following statements is true?
- There can only be a single on-point which always makes the condition true.
- There can be multiple on-points for a given condition which may or may not make the condition true.
- There can only be a single off-point which may or may not make the condition false.
- There can be multiple off-points for a given condition which always make the condition false.
Exercise 5.
A game has the following condition: numberOfPoints > 1024. Perform a boundary analysis.
Exercise 6.
Perform boundary analysis on the following decision: n % 3 == 0 && n % 5 == 0.
What are the on- and off-points?
Exercise 7. Which one of the following statements about the CORRECT principles is true?
- We assume that external dependencies are already on the right state for the test (REFERENCE).
- We test different methods from the same class in an isolated way in order to avoid order issues (TIME).
- Whenever we encounter a loop, we always test whether the program works for 0, 1, and 10 iterations (CARDINALITY).
- We always test the behaviour of our program when any expected data does not exist (EXISTENCE).
Exercise 8. We have a program called IsCat. It works as follows:
Given an list of prerequisites, it returns either the string "Cat" or the string "Doge". If the number of legs is an even number, it has a tail, the number of lives left is between [1, 9] inclusive, it has sharp nails and the sounds it produces is "miauw", it is a cat. In any other case, it is a doge.
First, do boundary analysis on the inputs. Think of on and off points for each of the conditions (while picking in points for the others). Next, apply the category/partition method. What are the minimal and most suitable partitions?
public class FelineValidator {
public static final String INVALID_CAT = "doge";
/**
* This function checks whether a certain animal is a cat.
* Given the following prerequisites:
* If the number of legs is an even number,
* it has a tail,
* the number of lives left is between [1, 9] inclusive,
* it has sharp nails, and
* the sounds it produces is "miauw" ...
* it is a cat.
* In any other case, it is a doge.
*
* @param numberOfLegs
* @param hasTail
* @param numberOfLives
* @param hasSharpNails
* @param sound
* @return String
*/
public String isCat(int numberOfLegs, boolean hasTail, int numberOfLives, boolean hasSharpNails, String sound) {
if (!(numberOfLegs % 2 == 0)) return INVALID_CAT;
if (!hasTail) return INVALID_CAT;
if (!(numberOfLives >= 1 && numberOfLives <= 9)) return INVALID_CAT;
if (!hasSharpNails) return INVALID_CAT;
if (!(sound.matches("miauw"))) return INVALID_CAT;
return "cat";
}
}
References
Jeng, B., & Weyuker, E. J. (1994). A simplified domain-testing strategy. ACM Transactions on Software Engineering and Methodology (TOSEM), 3(3), 254-270.
Chapter 7 of Pragmatic Unit Testing in Java 8 with Junit. Langr, Hunt, and Thomas. Pragmatic Programmers, 2015.
- Kaner, Cem, Sowmya Padmanabhan, and Douglas Hoffman. The Domain Testing Workbook. Context Driven Press, 2013.
- Kaner, Cem. What Is a Good Test Case?, 2003. URL: http://testingeducation.org/BBST/testdesign/Kaner_GoodTestCase.pdf